本文术语定义
本文中的术语:远程解压、远程计算、远程重计算是相同的含义,都是指GigaHorse挂盘中的显卡算力共享功能。
本文出现的解压机、解压服务器等都是指提供显卡算力的主机。
一、远程解压是什么、能做什么、你是否需要它
是什么?
将显卡算力共享给其他挂盘机有什么好处?
- 挂盘机无法插显卡的用户可以使用局域网其他主机内的显卡算力挂giga图
- 提高显卡的利用率
有什么缺点?
挂盘机需要运行的程序又多了一个,挂盘的软件架构更复杂,增加了设备运维的复杂度。你真的需要它吗?
如果挂盘机能插显卡,十分不建议使用远程解压的功能,原则是能不用就不用。
因为使用这个功能要额外运行专用的程序,在没有高效的运维监控程序的情况下有可能这个程序崩掉了你却不知道。
除非你的显卡在“大马拉小车”,比如:3090显卡插在了 24盘挂盘机上,确实有些浪费,可以通过远程计算的方式多主机共用这一个显卡,节省成本。
二、部署方案介绍
前四个是官方提供的部署案例,不建议实际部署时候按这四种方式,推荐第五种方式,原因在下面详细说。当然读者请根据自己的实际情况选择部署方案。
2.1 单独一台主机作为解压服务器
图片已经非常清晰,一台专门的机器A上插了2个显卡,运行chia_recompute_server程序将两个显卡的算力共享出去。
假设左边主机A的IP是:192.168.1.10,chia_recompute_server程序使用默认的端口11989,右侧的收割机只要在本机的操作系统环境变量(或start_farmer脚本内)设置环境变量 CHIAPOS_RECOMPUTE_HOST=192.168.1.10:11989 即可实现使用A主机的显卡进行挂盘解压工作。

2.2 两台主机作为解压服务器分摊负载
与例子1完全一样,提供算力共享的主机变成2台,假设A、B两台主机IP分别是:192.168.1.10、192.168.1.11,启动chia_recompute_server程序仍然使用默认的端口11989,此时中间的收割机只需要设置环境变量的值为: CHIAPOS_RECOMPUTE_HOST=192.168.1.10:11989,192.168.1.11 (注意第二台主机我没有设定端口,这样也是允许的,软件会自动使用默认的11989端口进行通信)。
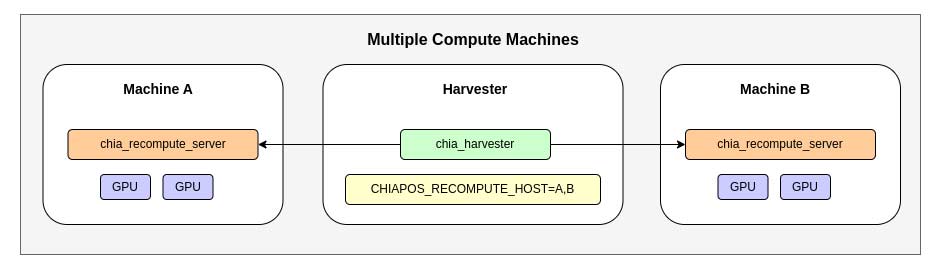
2.3 收割机同时使用自己本机和解压机的显卡挂盘
本例子将2.2中的收割机与B主机合二为一,使用本机的显卡也使用主机A的显卡解压挂盘。
这个例子更重要的作用是在提示我们,这个显卡算力共享的程序十分灵活,不与其他程序冲突,可以根据自己的情况灵活部署。

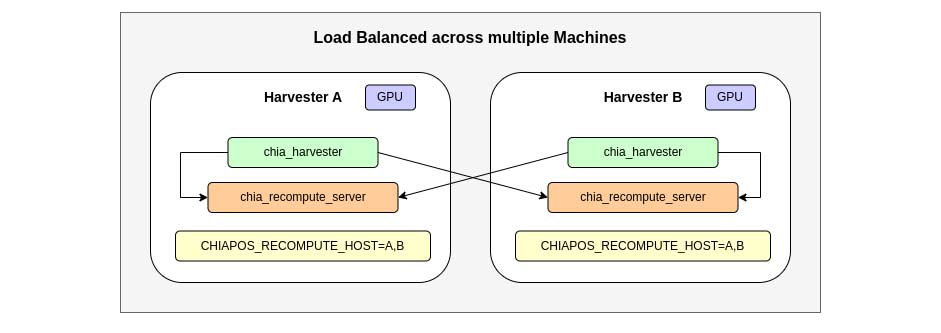
2.4 多台收割机之间互相对外共享算力
作者给这个方案起的名字是多主机的负载均衡,可能目的是想达到更高的容错能力,某台主机显卡挂掉仍然不影响挂盘。
图里虽然是两台收割机互相共享了自己的显卡算力,其实N台主机也可以。
N台挂盘机显卡算力溢出一部分很正常,给其他主机提供高可用能力也是不错的想法,但是giga挂盘显卡工作负载不高想坏都难,本着能不增加复杂度就不加的原则,十分不推荐这种用法。
2.5 代理人部署方式(强烈推荐)
看完上面四种方案你是否考虑过维护和配置这些解压专用主机的复杂程度。
假如你是个矿老板,有100台挂盘机都p好了giga压缩图,拿出了自己闲置的6台8卡以太矿机打算给这100台挂盘机做giga的挂盘算力支持,6台显卡机都启动了chia_recompute_server程序,然后将100台挂盘机的算力服务器指向了这6个主机的IP。
还记得设置方法吗?在每一台挂盘机设置环境变量
CHIAPOS_RECOMPUTE_HOST=主机1的IP,主机2的IP,主机3的IP,主机4的IP,主机5的IP,主机6的IP。
运行起来之后发现6台显卡机算力不足,想要再加两台,此时你需要再次手动在100台收割机上修改一遍环境变量,这是巨大的工作量!(如果你有远见,早就写好了批量修改所有主机参数的脚本,那也可以,当我没说)
下图的代理部署方式推荐给挂盘机比较多的矿工,不管有多少台挂盘机,它的解压机配置永远都是:CHIAPOS_RECOMPUTE_HOST=192.168.1.100,在挂盘机的视角看只有一台解压机可以使用,它并不知道实际上代理人身后有N台解压机在提供算力支持。以后增减、变动解压机只需要去代理主机上改动即可,十分方便。
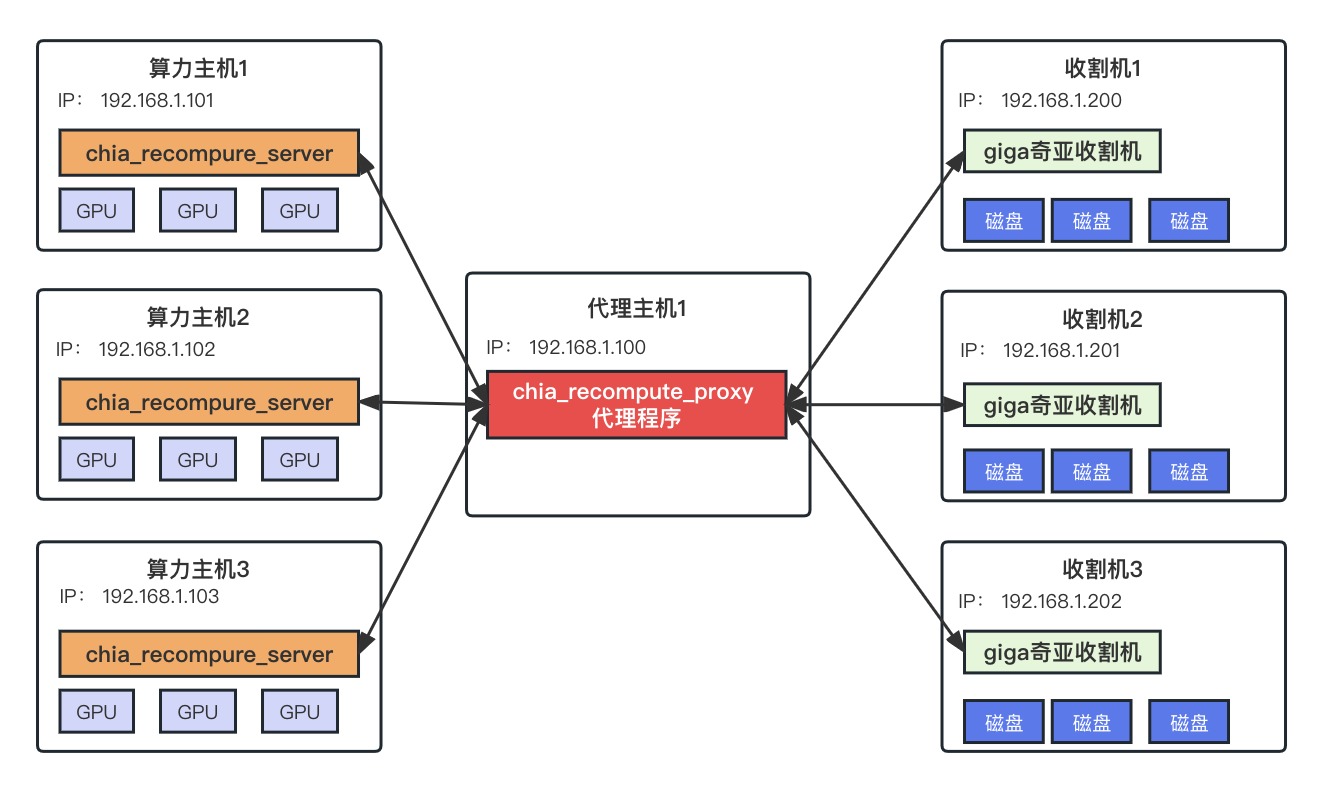
前面说过GigaHorse的程序部署十分灵活,将某一台解压机当做代理人也是可以的,比如下图这样:

三、实际部署设置方法
3.1 算力共享的程序在哪里
算力共享程序在GigaHorse的专用钱包中,本站提供的giga钱包国内镜像:Giga钱包下载 。
算力共享程序名叫做 chia_recompute_server.exe
算力代理程序叫做 chia_recompute_proxy.exe
3.2 显卡算力共享程序chia_recompute_server参数解析
程序参数非常简单,基本都有默认值,大部分用户都不必设定这些参数的值,直接启动该程序就可以使用了。
| 参数 | 默认值 | 用法解析 |
|---|---|---|
| -p | 11989 | 显卡共享服务的端口,收割机通过请求该端口获得算力支持 |
| --host | 0.0.0.0 | 显卡共享服务监听的主机,除非想限制非本机访问否则不要随便设置该参数 |
| -r | 环境变量CHIAPOS_MAX_CORES的值 | 解压功能使用的CPU核心数量,如果CHIAPOS_MAX_CORES未手动设定过默认是16,建议CPU核心多的用户手动设定该值,假如有64核心CPU可以设置成60 |
| -G | 环境变量 CHIAPOS_MAX_CUDA_DEVICES 的值 | 显卡共享服务使用的CUDA显卡限制。按照作者的描述假如你有两个显卡,将该值设置为1时,使用速度较快的显卡;将该值设置为0时则禁用所有显卡。 |
| -O | 环境变量 CHIAPOS_MAX_OPENCL_DEVICES 的值 | 显卡共享服务使用的OpenCL显卡选项。 设定值参考上面-G参数 |
| -g | all(所有显卡) | 显卡共享服务使用的CUDA显卡列表。默认使用本机的所有显卡,假如有3个显卡,它们的序号自然就是0、1、2,如果只想使用0和1的显卡,设定值:0,1 |
| -c | all(所有显卡) | 显卡共享服务使用的OpenCL显卡列表。 设定值同上-g参数。 |
用法举例:
3.2.1 将本机的所有显卡都作为giga的解压算力对外共享
执行命令: .\chia_recompute_server.exe
执行后可以看到如下输出:
D:\chia-gigahorse-farmer-14>.\chia_recompute_server.exe
[chiapos] Using 16 / 18 CPU threads 本机CPU有18个核心,server服务使用16个
[chiapos] Using 1 / 1 CUDA devices 本机有1个CUDA显卡,server服务使用1个
Using 16 / 18 CPU threads
Using NVIDIA GeForce RTX 3070 (CUDA (native)) 使用的显卡型号
ReComputeServer listening on 0.0.0.0 port 11989 server服务启动成功,监听的host是0.0.0.0,端口是11989
3.3 代理程序chia_recompute_proxy的参数解析
一定要理解当前的proxy程序只是个代理,它只是个中转程序,它自己不直接操作显卡,它只是将现有的chia_recompute_server显卡共享程序汇聚到一起,然后通过一个端口对其他收割机提供解压服务。
| 参数 | 默认值 | 用法解析 |
|---|---|---|
| -p | 11989 | 代理程序对外提供显卡共享服务的端口,收割机通过请求该端口获得算力支持。 |
| --host | 0.0.0.0 | 代理程序对外提供共享服务监听的主机,除非想限制非本机访问否则不要随便设置该参数 |
| -n | 无默认值 | 必填选项 ,设定的格式是host[:port]的格式,如果chia_recompute_server程序使用默认的11989端口,那么配置-n时候端口可以省略,如果有多个chia_recompute_server服务主机就配置N次。 例如: -n 192.168.1.5:11989 -n 192.168.1.6 -n 192.168.1.7 |
用法举例1:
执行命令: .\chia_recompute_proxy.exe -n localhost
该命令表示代理程序下属的共享server只有一个,就是localhost(本机),此时要求本机另外还要启动chia_recompute_server程序,并且运行在默认的11989端口上。
执行后可以看到如下输出:
D:\chia-gigahorse-farmer-14>.\chia_recompute_proxy.exe -n localhost
Node: localhost (port 11989)
ReComputeProxy listening on 0.0.0.0 port 11989
用法举例2:
执行命令: .\chia_recompute_proxy.exe -n 192.168.1.5 -n 192.168.1.6:11000
该命令表示代理程序下属的共享server只有2个,分别在192.168.1.5和192.168.1.6两台主机上其中192.168.1.6的主机使用了自定义的chia_recompute_server端口11000。
运行结果略。
3.4 进阶参数
chia_recompute_server 依赖GigaHorse修改的chiapos库,GigaHorse的专用chiapos库支持一些自定义参数如下表:
这些参数是GigaHorse专属的,在官方Chia相关的程序中不能使用。
| 变量名 | 默认值 | 解析 |
|---|---|---|
| CHIAPOS_MAX_CORES | 16 | 挂盘、显卡共享功能等相关使用chiapos库的功能使用的CPU核心数。设置的原则是:单显卡用户默认不用改、CPU挂盘用户尽可能大(不能超过实际核心数,低于16就按填默认的16)、多卡用户安装显卡数x8的数值配置。 |
| CHIAPOS_MAX_GPU_DEVICES | 最大cuda或OpenCL设备数 | |
| CHIAPOS_MAX_CUDA_DEVICES | 最大cuda设备数,会覆盖 CHIAPOS_MAX_GPU_DEVICES的值 | |
| CHIAPOS_MAX_OPENCL_DEVICES | 最大OpenCL设备数,会覆盖 CHIAPOS_MAX_GPU_DEVICES 的值 | |
| CHIAPOS_MIN_GPU_LOG_ENTRIES | 21 | minimum work size for GPU, can be set to modify transition to GPU based on C level (default = 21) |
| CHIAPOS_RECOMPUTE_HOST | 收割机使用的远程显卡算力服务主机的IP列表,用英文逗号“,”分隔,HOST 或HOST:PORT格式 |
|
| CHIAPOS_RECOMPUTE_PORT | 共享显卡算力程序chia_recompute_server的服务端口 | |
| CHIAPOS_RECOMPUTE_TIMEOUT | 5000 | 每次收割机请求远程显卡主机进行解压的超时时间,单位:毫秒。默认5000表示5秒钟。 |
| CHIAPOS_RECOMPUTE_CONNECT_TIMEOUT | 2000 | 收割机连接远程显卡主机的超时时间,单位:毫秒。默认的2000表示2秒钟。 |
| CHIAPOS_RECOMPUTE_RETRY_INTERVAL | 100 | 当远程显卡解压主机无法提供服务时下次重试的时间间隔时间。单位:秒。假如有3台显卡解压机,其中一个挂掉无法提供服务,收割机会在100秒后再次尝试连接。个人建议默认即可,即使自己修改也不要调得特别低。 |
3.5 实战
3.5.1 收割机连接远程显卡解压的配置方法
假设已经在有显卡的主机上启动了chia_recompute_server服务,IP是192.168.1.5,端口是默认的11989。
此时在收割机上设定CHIAPOS_RECOMPUTE_HOST这个环境变量为192.168.1.5即可。
以Windows为例,最简单的设置方法是修改giga钱包的启动脚本start_harvester.cmd文件,在其中添加一行:set CHIAPOS_RECOMPUTE_HOST=192.168.1.5:11989 保存即可,双击start_harvester.cmd脚本启动收割机,随后在chia_recompute_server 的窗口中可以看到有请求日志进来。
@ECHO OFF
setlocal
set CHIAPOS_RECOMPUTE_HOST=192.168.1.5:11989
start "Chia Gigahorse" cmd.exe /K ".\chia.exe start harvester"
:EXIT
endlocal
Linux版本的giga钱包中并未提供现成的start_harvester.sh脚本,自己新建一个,填入以下内容保存。
新建脚本还不能直接执行,使用命令给start_harvester.sh脚本授权:sudo chmod +x start_harvester.sh
以后使用该命令启动收割机:./start_harvester.sh
#!/bin/bash
export CHIAPOS_RECOMPUTE_HOST=192.168.1.5:11989
./chia.bin start harvester
四、常见问题
4.1 、收割机和chia_recompute_server的程序不同操作系统可以吗?
可以,都是http协议通信,不区分操作系统。